Imagen generada con ChatGPT. La inteligencia artificial no es una autoridad. Es, más bien, una agregación estadística de lo que Internet dice en voz alta.
El pasado jueves leí una nota de Pilar N. Colorado:
Coincido totalmente con su visión. Sospecho que este tipo de conversaciones será cada vez más frecuente y tendremos que combatir un sesgo de autoridad que otorga a lo que dice un modelo de lenguaje veracidad automática.
Con este artículo, aprovechando la inspiración que me brindó Pilar, me propongo ampliar cómo se entrena un modelo y por qué animo a desconfiar y cuestionar sus respuestas siempre. Quizá el mayor problema no sean las alucinaciones, sino las verdades a medias.
🕒 Resumen para gente con prisa
Tiempo estimado de lectura del artículo completo: 14 minutos.
La IA no es una autoridad ni una fuente de verdad: es una agregación estadística de lo que Internet dice en voz alta. Suena convincente porque escribe bien, no porque tenga criterio. El peligro no son tanto las alucinaciones como las verdades a medias que aceptamos sin cuestionar.
Los modelos heredan sesgos inevitables: mandan los contenidos más abundantes, el tono se confunde con autoridad y tendemos a quedarnos con lo que confirma nuestras ideas. La IA no “entiende” el mundo; reproduce patrones de datos desiguales, incompletos y, a veces, manipulados.
La solución no es dejar de usarla, sino usar método: pedir fuentes, comparar perspectivas, exigir grados de certeza, preguntar por sesgos y verificar especialmente aquello que creemos conocer. La IA debe ayudar a pensar, no a decidir por nosotros.
En un contexto donde incluso los datos se degradan y se reciclan entre máquinas, la única defensa real sigue siendo la de siempre: criterio, contraste y pensamiento crítico. Porque, si la IA es tu socia, conviene recordarlo: desconfía de tus socios.
Cómo se entrena realmente un modelo de lenguaje
Los modelos de lenguaje actuales, como ChatGPT, Claude, Gemini o Llama, se entrenan así, de forma muy simplificada:
- Consumen cantidades masivas de texto: libros, artículos, documentos públicos, páginas web, foros, código, conversaciones… Cualquier cosa que esté disponible en la red (a veces legalmente y otras no tanto) y con un volumen suficiente.
- Aprenden patrones estadísticos: qué palabra tiende a seguir a otra, cómo se estructura un argumento, cómo se escribe una receta, cómo suele responder un médico o un ingeniero, etc.
- Se afinan con supervisión humana: evaluadores que corrigen respuestas, premian las útiles y penalizan las peligrosas o incorrectas. Esto reduce errores, pero no elimina los sesgos originales.
- Se ajustan para ser más seguros, coherentes y educados mediante técnicas como RLHF, Constitutional AI o modelos de razonamiento externo.
El resultado no es una enciclopedia ni las bibliotecas infinitas del universo de Borges. Es un gran compresor de lenguaje que reproduce patrones estadísticos de lo que ha visto.
Y he aquí la clave: si en el entrenamiento hay más ruido que señal, el modelo aprenderá más ruido que señal. No porque nos quiera engañar, sino porque simplemente refleja la proporción y la calidad de lo que ha ingerido.
Los sesgos: inevitables, implícitos y, a veces, peligrosos
Considero que hay tres sesgos que debemos tener muy en cuenta cuando usamos un LLM:
1. Sesgo de disponibilidad
El contenido más abundante tiene una mayor influencia en la respuesta. Si alimentamos al modelo con mil blogs sobre una dieta milagrosa y apenas diez estudios científicos desmontándola, el modelo reflejará esa asimetría. Es decir, salvo que se ajuste manualmente el entrenamiento, el modelo dará más peso a los blogs que a los estudios.
2. Sesgo de autoridad percibida
Cuando la IA responde con tono seguro, mucha gente interpreta la frase como un acto de autoridad. El modelo no tiene “confianza”, tan sólo probabilidad estadística de que la frase que escupe es buena. Como suena convincente porque está bien escrita, a la mayoría le basta con eso.
3. Sesgo de confirmación
Las personas tienden a leer (y aceptar) aquello que confirma sus ideas previas. La IA amplifica este efecto porque te entrega argumentos limpios, ordenados y fáciles de procesar. Los hijos de Pilar eligieron exactamente lo que reforzaba su posición, como hacemos casi todos.
Dos ejemplos sencillos que muestran estos sesgos en acción
A veces pensamos que estos sesgos sólo afectan a temas complejos como política, salud o psicología. Pero lo cierto es que aparecen también en tareas aparentemente inocuas. Dos ejemplos clásicos lo ilustran muy bien1.
El reloj analógico imposible
Pide a un generador de imágenes:
“Un reloj analógico marcando las 17:40”.
En 2023 era casi imposible que acertara. Hoy ha mejorado… pero sigue fallando sorprendentemente a menudo: agujas mal alineadas, horas imposibles, proporciones incorrectas. ¿Por qué? En primer lugar, la mayoría de imágenes de relojes en la web no están etiquetadas con la hora concreta. También sucede que la geometría de agujas y ángulos es difícil para modelos que no razonan espacialmente. Y sobre todo, porque muchas fotos muestran la estética “10:10” típica de publicidad.
No es que la IA “no entienda los relojes”, sino que aprende de ejemplos ambiguos, desiguales y poco precisos.
Los quiméricos zurdos
Ahora, pídele esto:
“Retrato de una persona zurda escribiendo con la mano izquierda”.
Lo más probable es que el modelo genere a alguien escribiendo con la mano derecha.
¿Por qué? Muy simple. El 90% de la población es diestra y así aparece en la mayoría de fotos. Los zurdos somos una rara avis, también para las máquinas. Y al igual que con los relojes, las descripciones de imágenes rara vez mencionan la mano dominante. Por lo tanto, el modelo rellena el hueco con lo más estadísticamente probable.
Aquí, el sesgo no es sólo técnico, sino sobre todo estadístico y cultural: es un reflejo directo de la distribución real de datos en Internet. El modelo replica mayorías porque no tiene criterio para valorar la importancia de la minoría.
Estos ejemplos, aparentemente triviales, muestran una verdad incómoda: la IA no entiende el mundo; entiende los patrones del contenido del que se alimenta. Y cuando los datos están desequilibrados, incompletos o mal etiquetados, la IA reproduce exactamente esos fallos.
¿Cómo evitar que la IA se convierta en un manipulador amable?
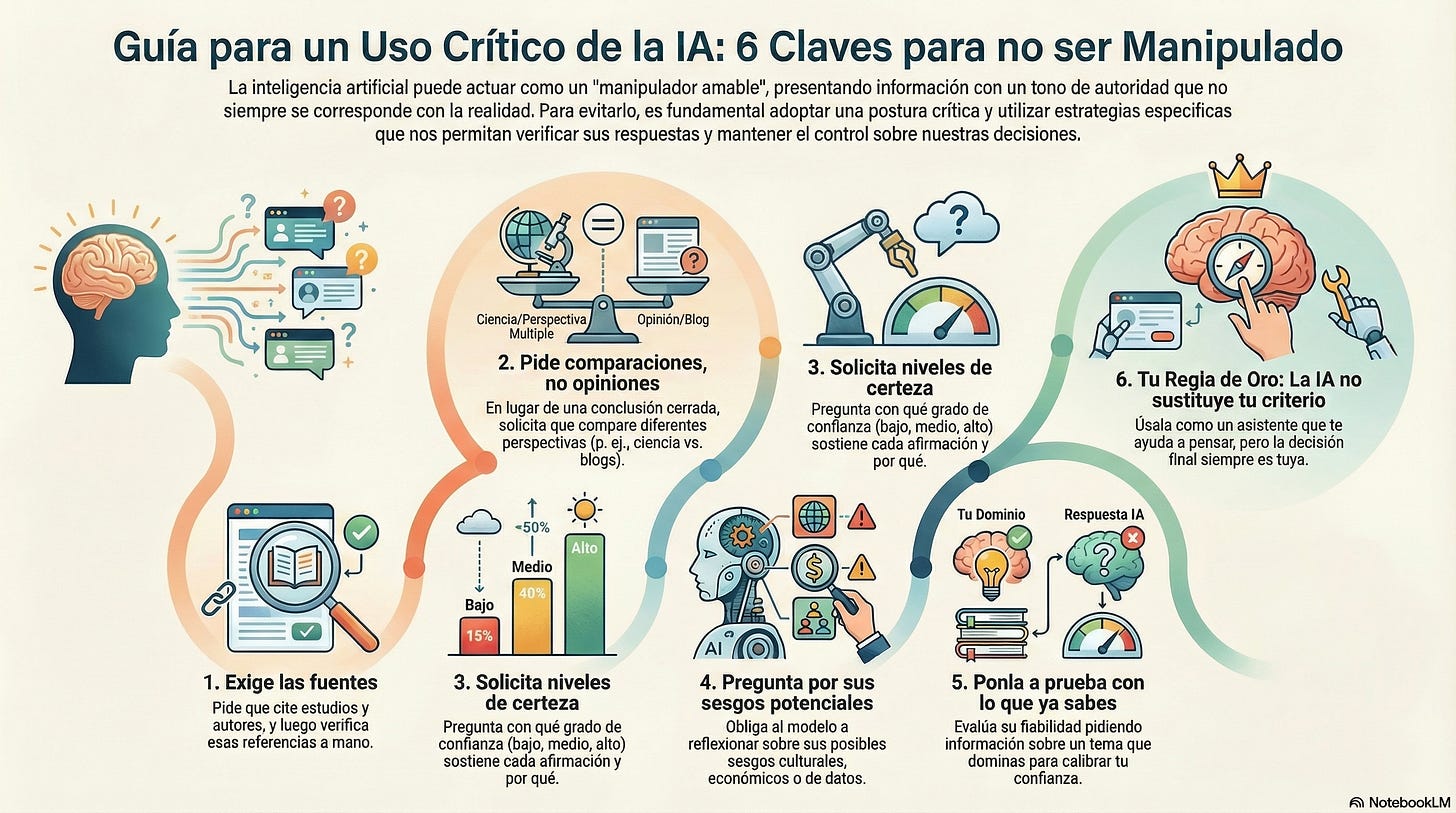
Imagen generada con NotebookLM. Aquí una serie de prácticas útiles, tanto para adolescentes como para adultos:
1. Dame tus fuentes
No le preguntes “qué es verdad”, sino cuáles son sus fuentes. No es periodista, así que tiene que dártelas. Y conforme la regulación se desarrolle, esto se irá asentando como una buena práctica en todos los modelos.
Puedes incorporar a tus prompts algo así:
“Cita estudios concretos, autores, instituciones, fechas y bibliografía que respalde tus afirmaciones”.
Y verifícalas a mano. No es la primera vez que me da unas referencias curradísimas que llevan a enlaces rotos o son puras invenciones con mucho estilo.
En caso de que no te las diera, pídele más contexto o usa otro modelo.
2. Comparación > Opinión
La pregunta “¿qué opinas?” invita a respuestas redondas, además de que un modelo no tiene experiencias, intereses ni valores propios.
Si, en cambio, le pides una comparación estricta, puedes sacarle mucho más jugo:
“Compara lo que dice la evidencia científica con lo que dicen los blogs comerciales”.
El cambio de enfoque es importante: en lugar de pedirle una conclusión cerrada, lo obligas a buscar otras perspectivas.
3. Solicita grados de confianza
Algunos modelos permiten esto de forma nativa (aquí, Claude sobresale). En otros lo puedes forzar tú con la formulación de la pregunta:
“¿Con qué nivel de certeza (bajo/medio/alto) sostienes cada afirmación y por qué?”
Obligarle a explicitar el grado de confianza tiene varios efectos colaterales interesantes:
- Te obliga a dejar de ver la respuesta como un “sí” o “no” y a pensar en términos de probabilidad.
- Te permite distinguir entre cosas bien establecidas (por ejemplo, conceptos físicos básicos) y temas donde la evidencia es débil, contradictoria o está en desarrollo.
- Te da pistas de por dónde empezar a contrastar. Una afirmación con “confianza alta” pero que te chirría es una candidata ideal para ir a las fuentes primarias y ver quién se está equivocando, si tú, el modelo o ambos.
Una buena práctica es pedir que el modelo te devuelva algo así como:
- Afirmación → nivel de certeza → breve justificación.
Funciona especialmente bien en temas de salud, economía, predicciones o recomendaciones de impacto alto. Aunque, como los modelos hacen bien en advertir y yo nunca me cansaré de recomendar: nunca dejes tu salud en manos de un LLM, a no ser que no te importe tu vida.
4. Pregunta por los sesgos potenciales
Formulaciones del tipo:
¿Qué sesgos podrían estar afectando a tu respuesta?¿Desde qué perspectiva cultural, geográfica o económica estás respondiendo?
obligan al modelo a hacer autocrítica, o algo muy parecido. Y eso, aunque no elimine el sesgo, lo hace visible, que ya es media victoria.
Algunos ejemplos de sesgos frecuentes que la propia IA puede reconocer:
- Respuestas centradas en contexto estadounidense cuando la pregunta es “global”.
- Asumir estructuras familiares, laborales o educativas que no aplican a tu país.
- Priorizar fuentes comerciales porque están mejor posicionadas o redactadas.
Si vas a tomar decisiones importantes, no es mala idea añadir, al final de la interacción:
“Resume en una lista qué limitaciones y sesgos tiene todo lo que acabas de decir.”
Es como adjuntar una nota legal al informe, pero generada por la propia herramienta.
5. Verifica siempre un tema que conozcas
Antes de fiarte de un modelo, somételo al “test de lo que yo ya sé”. Pide información sobre tu ámbito profesional, un hobby que domines, un libro o una película que conozcas al detalle, un tema concreto de historia o ciencia que tengas muy trabajado. Y fíjate en qué cosas acierta, cuáles simplifica de más, dónde se las inventa con aparente seguridad…
Este ejercicio cumple dos objetivos:
- Calibras tu confianza en ese modelo concreto. No todos tienen la misma calidad ni la misma cobertura temática.
- Afinas tu detector de bulos. Aprendes a reconocer señales de alarma: frases demasiado redondas, ausencia de matices, afirmaciones categóricas en temas donde tú sabes que nadie puede ser tan tajante.
Con adolescentes se puede convertir en un juego: “vamos a pillar a la IA”. Es una forma amable de introducir pensamiento crítico sin que parezca una charla moralizante.
6. Tu regla de oro: la IA no sustituye el criterio
La IA puede acelerar, resumir, estructurar, sugerir enfoques que no se te habían ocurrido. Pero no debe ser fuente de verdad única ni final.
Si la usamos como calculadora avanzada para ordenar información, generar borradores, sugerir preguntas que no habíamos hecho, es una aliada fantástica.
El problema empieza cuando la dejamos actuar como juez en lugar de como asistente. Cuando la respuesta del modelo cierra la conversación en lugar de abrirla. Ahí es donde entramos en modo “piloto automático cognitivo”: dejamos de pensar porque “ya lo ha pensado la máquina”.
La regla de oro podría ser algo así:
La IA me ayuda a pensar, pero la decisión final es mía.Y asumo sus consecuencias.
En temas sensibles —salud, educación de los hijos, decisiones financieras, decisiones laborales serias— esto implica siempre:
- Contrastar con fuentes humanas cualificadas.
- Leer, aunque dé pereza, las piezas largas (artículos, estudios, informes).
- Hablar con otras personas y no sólo con modelos.
7. Añade un pie de prompt para subir el listón
Si utilizas la IA con frecuencia, te puede ayudar tener un pie de prompt estándar que añadas al final de tus preguntas para forzar un mínimo de rigor.
Te propongo (y te regalo) el megaprompt de verificación total en dos versiones, corta y larga: Megaprompito (para no fundirte los tokens)
Indica tus fuentes, señala el grado de certeza de cada afirmación y menciona posibles sesgos o limitaciones de tu respuesta. Megaprompt (para decisiones de vida o muerte) Megaprompt de higiene mínima
A partir de ahora, cuando respondas a mis preguntas:
Indica explícitamente cuál es el tipo de pregunta (definición, explicación, opinión común, evidencia científica, consejo práctico, etc.).
Cita, cuando sea posible, estudios, autores, instituciones o fuentes relevantes, y marca claramente cuándo algo es consenso científico y cuándo es opinión o práctica habitual.
Señala el grado de certeza de cada afirmación importante (bajo/medio/alto) y explica brevemente por qué.
Enumera al menos tres sesgos o limitaciones potenciales de tu respuesta. Por ejemplo, sesgos culturales, de idioma, de disponibilidad de datos, de fecha de actualización…
Indica explícitamente qué partes de tu respuesta podrían estar desactualizadas o ser controvertidas según el estado actual del conocimiento.
Termina siempre con una sección titulada ‘Cómo puedo verificar esto’ con sugerencias concretas de verificación por mi cuenta: tipos de fuentes a consultar, palabras clave, profesionales a los que acudir…
Si alguna parte de lo que te pido no puedes hacerla, dilo de forma explícita y explica por qué.
No es una garantía absoluta de nada, pero sube el listón de la conversación. Conviertes la “charla con la máquina” en un proceso con unos mínimos de transparencia y contraste.
Cuando los datos también se corrompen
Hasta ahora hemos hablado de cómo preguntamos y de cómo interpretamos las respuestas de un modelo. Pero hay un problema más profundo y menos visible: la calidad y la naturaleza de los datos con los que se entrenan estas máquinas.
Los modelos no aprenden del conocimiento humano en abstracto, sino de aquello a lo que pueden acceder. Y ahí aparece la primera grieta importante. Gran parte del contenido de mayor valor (investigación científica de calidad, libros técnicos, análisis profundos, periodismo riguroso) está protegido por muros de pago, licencias restrictivas o formatos que no son fácilmente aprovechables para el entrenamiento masivo. En cambio, el contenido superficial, comercial o directamente mediocre suele estar disponible en abierto, en cantidades industriales y con una estructura perfectamente digerible para un algoritmo.
El resultado es incómodo. Mientras que mucho del mejor conocimiento queda fuera, el ruido entra sin apenas fricción. No porque los modelos “prefieran” el ruido, sino porque es lo que abunda y lo que pueden consumir. Cuando una IA responde con soltura citando blogs, guías genéricas u opiniones ampliamente aceptadas, lo que estamos viendo no es criterio, sino disponibilidad.
A esto se suma un fenómeno aún más preocupante: el envenenamiento deliberado de los datos. Si sabemos que lo que se publica hoy puede acabar influyendo en los modelos de mañana, es ingenuo pensar que nadie intentará explotar ese canal. Narrativas repetidas de forma coordinada, pseudoestudios disfrazados de rigor técnico o documentación sesgada con apariencia neutral pueden acabar formando parte del sustrato estadístico del que beben los modelos. La IA no tiene un detector interno de intenciones; si el contenido supera unos filtros mínimos, lo incorpora como un patrón más.
Pero incluso sin mala fe, existe otro riesgo silencioso: la retroalimentación entre modelos. Cada vez más contenido en la red está generado total o parcialmente por otras IAs. Si los modelos futuros se entrenan sobre textos, imágenes y resúmenes producidos por modelos anteriores, entramos en un bucle peligroso. Se pierde diversidad, se repiten estructuras, se consolidan errores y las alucinaciones pueden acabar pareciendo verdades simplemente porque están bien distribuidas. El conocimiento no evoluciona: se recicla y se empobrece.
A todo esto hay que añadir el factor tiempo. Los modelos no viven en presente continuo. Trabajan con ventanas temporales, con cortes, con información que puede haber quedado obsoleta sin que el usuario sea consciente de ello. Una respuesta puede sonar perfectamente actual y, sin embargo, estar anclada en un consenso que ya ha cambiado o en un debate que ha evolucionado de forma significativa.
Todo esto nos lleva a una conclusión incómoda pero necesaria: no basta con pedirle más rigor a la máquina. Mientras los datos de entrenamiento sigan siendo desiguales, incompletos o fácilmente manipulables, el problema no se resuelve a base de mejores prompts o modelos más grandes. La responsabilidad última sigue estando en quien consulta, interpreta y decide qué hacer con la respuesta.
La IA puede amplificar el conocimiento humano, pero también puede amplificar sus defectos. Y mientras no tengamos ecosistemas de datos más sanos, diversos y bien gobernados, la única defensa real sigue siendo la misma de siempre: criterio, contraste y pensamiento crítico.
Crítica, crítica, crítica
Parafraseando a Julio Anguita con su famoso “programa, programa, programa”, lo que propongo es el pensamiento crítico en su máxima expresión. Si antes teníamos que coger con pinzas la información que recibíamos en redes sociales, ahora es mucho más urgente y necesario.
La IA puede ser un gran aliado si la usamos con cabeza y precaución. La maquinaria peligrosa requiere medidas de seguridad acordes. La IA no es peligrosa per se, pero puede serlo si aceptamos sin rechistar todo lo que nos diga. Tenemos la responsabilidad de aprovechar todo el potencial que nos ofrece sin convertirnos en meros espectadores pasivos sin capacidad de juicio.
Si te quieres quedar con una frase, teniendo en cuenta que los modelos son nuestros nuevos socios en casi todo lo que hacemos, te propongo la de la famosa canción de Presuntos Implicados:
“Desconfía de tus socios”.
1 Antes de seguir, una aclaración importante: los ejemplos de sesgos que propongo no son de modelos de lenguaje puros, sino de generación de imágenes. Aun así, el fenómeno es exactamente el mismo. Hablemos de texto o de imagen, estamos ante modelos entrenados sobre grandes volúmenes de datos que reproducen los sesgos, desequilibrios y limitaciones de aquello que han visto. La arquitectura cambia; no así el problema de fondo.