Image generated with ChatGPT. Artificial intelligence is not an authority. It is, rather, a statistical aggregation of what the Internet loudly proclaims.
Last Thursday, I read a note by Pilar N. Colorado:
I completely agree with her view. I suspect that this type of conversation will become increasingly common, and we will have to combat an authority bias that grants automatic truth to what a language model says.
With this article, inspired by Pilar, I aim to expand on how a model is trained and why I encourage skepticism and questioning of its responses at all times. Perhaps the biggest problem is not the hallucinations, but the half-truths.
🕒 Summary for busy people
Estimated reading time for the full article: 14 minutes.
AI is neither an authority nor a source of truth: it is a statistical aggregation of what the Internet loudly proclaims. It sounds convincing because it writes well, not because it has judgment. The danger is not so much the hallucinations as the half-truths we accept without questioning.
Models inherit inevitable biases: the most abundant content prevails, tone is confused with authority, and we tend to stick with what confirms our ideas. AI does not “understand” the world; it reproduces patterns from unequal, incomplete, and sometimes manipulated data.
The solution is not to stop using it, but to use method: ask for sources, compare perspectives, demand degrees of certainty, inquire about biases, and especially verify what we believe we know. AI should help us think, not decide for us.
In a context where even data degrades and recycles among machines, the only real defense remains the same: judgment, contrast, and critical thinking. Because if AI is your partner, it’s worth remembering: distrust your partners.
How a language model is really trained
Current language models, such as ChatGPT, Claude, Gemini, or Llama, are trained like this, in a very simplified way:
- They consume massive amounts of text: books, articles, public documents, websites, forums, code, conversations… Anything available on the web (sometimes legally and sometimes not) and in sufficient volume.
- They learn statistical patterns: what word tends to follow another, how an argument is structured, how a recipe is written, how a doctor or an engineer usually responds, etc.
- They are fine-tuned with human supervision: evaluators who correct responses, reward useful ones, and penalize dangerous or incorrect ones. This reduces errors but does not eliminate original biases.
- They are adjusted to be more safe, coherent, and polite using techniques like RLHF, Constitutional AI, or external reasoning models.
The result is not an encyclopedia or the infinite libraries of Borges’ universe. It is a large language compressor that reproduces statistical patterns of what it has seen.
And here lies the key: if there is more noise than signal in the training, the model will learn more noise than signal. Not because it wants to deceive us, but simply because it reflects the proportion and quality of what it has ingested.
Biases: inevitable, implicit, and sometimes dangerous
I believe there are three biases we must keep in mind when using an LLM:
1. Availability bias
The most abundant content has a greater influence on the response. If we feed the model with a thousand blogs about a miracle diet and only ten scientific studies debunking it, the model will reflect that asymmetry. In other words, unless the training is manually adjusted, the model will give more weight to the blogs than to the studies.
2. Perceived authority bias
When AI responds confidently, many people interpret the statement as an act of authority. The model does not have “confidence,” just a statistical probability that the statement it produces is good. Since it sounds convincing because it is well-written, that is enough for most people.
3. Confirmation bias
People tend to read (and accept) what confirms their prior ideas. AI amplifies this effect because it delivers clean, organized, and easy-to-process arguments. Pilar’s children chose exactly what reinforced their position, just as we all do.
Two simple examples that show these biases in action
Sometimes we think these biases only affect complex topics like politics, health, or psychology. But the truth is they also appear in seemingly innocuous tasks. Two classic examples illustrate this very well1.
The impossible analog clock
Ask an image generator:
“An analog clock showing 5:40 PM.”
In 2023, it was almost impossible for it to get it right. Today it has improved… but it still fails surprisingly often: misaligned hands, impossible hours, incorrect proportions. Why? First, most clock images on the web are not labeled with the specific time. It also happens that the geometry of hands and angles is difficult for models that do not reason spatially. And above all, because many photos show the typical “10:10” aesthetic of advertising.
It’s not that AI “doesn’t understand clocks,” but rather that it learns from ambiguous, unequal, and imprecise examples.
The chimeric left-handers
Now, ask it this:
“Portrait of a left-handed person writing with their left hand.”
Most likely, the model will generate someone writing with their right hand.
Why? Very simple. 90% of the population is right-handed, and that is how it appears in most photos. Left-handers are a rare species, even for machines. And just like with clocks, image descriptions rarely mention the dominant hand. Therefore, the model fills the gap with what is statistically most probable.
Here, the bias is not only technical but also statistical and cultural: it is a direct reflection of the real data distribution on the Internet. The model replicates majorities because it has no judgment to assess the importance of the minority.
These seemingly trivial examples reveal an uncomfortable truth: AI does not understand the world; it understands the patterns of the content it feeds on. And when the data is unbalanced, incomplete, or poorly labeled, AI reproduces exactly those flaws.
How to prevent AI from becoming a friendly manipulator?
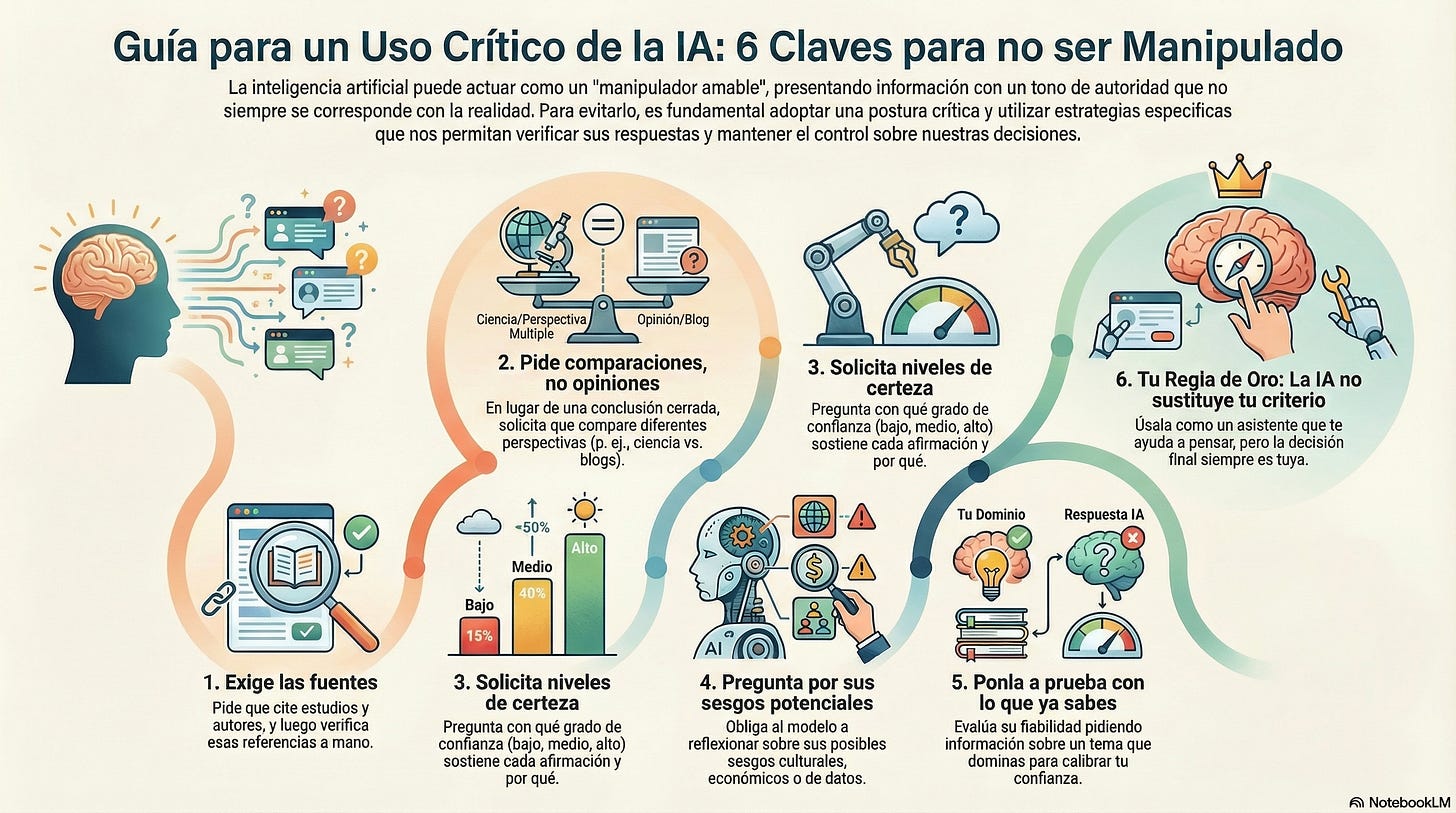
Image generated with NotebookLM. Here are a series of useful practices, for both teenagers and adults:
1. Give me your sources
Don’t ask it “what is true,” but rather what its sources are. It is not a journalist, so it must provide them. And as regulation develops, this will settle as a good practice across all models.
You can incorporate something like this into your prompts:
“Cite specific studies, authors, institutions, dates, and bibliography that support your claims.”
And verify them manually. It’s not the first time it has given me some very polished references that lead to broken links or are pure fabrications with great style.
If it doesn’t provide them, ask for more context or use another model.
2. Comparison > Opinion
The question “what do you think?” invites round answers, in addition to the fact that a model has no experiences, interests, or values of its own.
If, on the other hand, you ask for a strict comparison, you can extract much more value:
“Compare what the scientific evidence says with what commercial blogs say.”
The change in focus is important: instead of asking for a closed conclusion, you force it to seek other perspectives.
3. Request degrees of confidence
Some models allow this natively (here, Claude excels). In others, you can force it with the formulation of the question:
“What level of certainty (low/medium/high) do you hold for each statement and why?”
Forcing it to specify the degree of confidence has several interesting side effects:
- It forces you to stop seeing the answer as a “yes” or “no” and to think in terms of probability.
- It allows you to distinguish between well-established things (for example, basic physical concepts) and topics where the evidence is weak, contradictory, or under development.
- It gives you clues on where to start contrasting. A statement with “high confidence” but that feels off is an ideal candidate to go to primary sources and see who is mistaken, whether you, the model, or both.
A good practice is to ask the model to return something like:
- Statement → level of certainty → brief justification.
It works especially well in health, economics, predictions, or high-impact recommendations. Although, as models do well to warn and I will never tire of recommending: never leave your health in the hands of an LLM, unless you don’t care about your life.
4. Ask about potential biases
Formulations like:
What biases might be affecting your response? From what cultural, geographical, or economic perspective are you responding?
or compel the model to engage in self-criticism, or something very similar. And that, while it may not eliminate bias, makes it visible, which is already half the victory.
Some examples of common biases that AI itself can recognize:
- Responses centered on a U.S. context when the question is “global.”
- Assuming family, work, or educational structures that do not apply to your country.
- Prioritizing commercial sources because they are better positioned or written.
If you are going to make important decisions, it’s not a bad idea to add, at the end of the interaction:
“Summarize in a list what limitations and biases everything you just said has.”
It’s like attaching a legal note to the report, but generated by the tool itself.
5. Always verify a topic you know
Before trusting a model, subject it to the “test of what I already know.” Ask for information about your professional field, a hobby you master, a book or movie you know in detail, a specific historical or scientific topic you have worked on extensively. And pay attention to what it gets right, what it oversimplifies, where it invents things with apparent confidence…
This exercise serves two purposes:
- You calibrate your trust in that specific model. Not all have the same quality or thematic coverage.
- You sharpen your bullshit detector. You learn to recognize warning signs: overly rounded phrases, lack of nuance, categorical statements on topics where you know no one can be so definitive.
With teenagers, it can turn into a game: “let’s catch the AI”. It’s a gentle way to introduce critical thinking without it seeming like a moralizing talk.
6. Your golden rule: AI does not replace judgment
AI can accelerate, summarize, structure, and suggest approaches you hadn’t thought of. But it should not be a single or final source of truth.
If we use it as an advanced calculator to organize information, generate drafts, and suggest questions we hadn’t asked, it is a fantastic ally.
The problem starts when we let it act as judge instead of as assistant. When the model’s response closes the conversation instead of opening it. That’s when we enter “cognitive autopilot” mode: we stop thinking because “the machine has already thought it through.”
The golden rule could be something like:
AI helps me think, but the final decision is mine. And I take responsibility for its consequences.
In sensitive matters—health, child education, financial decisions, serious work decisions—this always implies:
- Contrasting with qualified human sources.
- Reading, even if it’s tedious, long pieces (articles, studies, reports).
- Talking to other people and not just models.
7. Add a prompt footer to raise the bar
If you frequently use AI, it may help to have a standard prompt footer that you add at the end of your questions to enforce a minimum level of rigor.
I propose (and gift you) the total verification megaprompt in two versions, short and long: Megaprompt (to avoid burning your tokens)
Indicate your sources, specify the degree of certainty of each statement, and mention possible biases or limitations of your response. Megaprompt (for life-or-death decisions) Minimum hygiene megaprompt
From now on, when you respond to my questions:
Explicitly indicate what type of question it is (definition, explanation, common opinion, scientific evidence, practical advice, etc.).
Cite, when possible, studies, authors, institutions, or relevant sources, and clearly mark when something is scientific consensus and when it is opinion or common practice.
Indicate the degree of certainty of each important statement (low/medium/high) and briefly explain why.
List at least three potential biases or limitations of your response. For example, cultural biases, language biases, data availability biases, update date biases…
Explicitly indicate which parts of your response might be outdated or controversial according to the current state of knowledge.
Always end with a section titled ‘How can I verify this’ with concrete verification suggestions for me: types of sources to consult, keywords, professionals to approach…
If there is any part of what I ask that you cannot do, say so explicitly and explain why.
It’s not an absolute guarantee of anything, but it raises the bar of the conversation. You turn “talking to the machine” into a process with minimum transparency and contrast.
When data also gets corrupted
So far, we have talked about how we ask and how we interpret the responses of a model. But there is a deeper and less visible problem: the quality and nature of the data with which these machines are trained.
Models do not learn from human knowledge in the abstract, but from what they can access. And here lies the first significant crack. Much of the most valuable content (quality scientific research, technical books, in-depth analysis, rigorous journalism) is protected by paywalls, restrictive licenses, or formats that are not easily usable for mass training. In contrast, superficial, commercial, or directly mediocre content is often available openly, in industrial quantities, and with a structure perfectly digestible for an algorithm.
The result is uncomfortable. While much of the best knowledge remains outside, the noise enters with hardly any friction. Not because models “prefer” noise, but because it is what abounds and what they can consume. When an AI responds fluently citing blogs, generic guides, or widely accepted opinions, what we are seeing is not judgment, but availability.
This is compounded by an even more concerning phenomenon: the deliberate poisoning of data. If we know that what is published today may influence tomorrow’s models, it is naive to think that no one will try to exploit that channel. Narratives repeated in a coordinated manner, pseudo-studies disguised as technical rigor, or biased documentation with a neutral appearance can end up forming part of the statistical substrate from which models draw. AI has no internal detector of intentions; if the content passes some minimal filters, it incorporates it as another pattern.
But even without malice, there is another silent risk: the feedback loop between models. More and more content on the web is generated wholly or partially by other AIs. If future models are trained on texts, images, and summaries produced by previous models, we enter a dangerous loop. Diversity is lost, structures are repeated, errors are consolidated, and hallucinations may end up seeming like truths simply because they are well-distributed. Knowledge does not evolve: it recycles and impoverishes.
To all this, we must add the factor of time. Models do not live in the present continuous. They work with time windows, with cuts, with information that may have become outdated without the user being aware of it. A response may sound perfectly current and yet be anchored in a consensus that has already changed or in a debate that has evolved significantly.
All of this leads us to an uncomfortable but necessary conclusion: it is not enough to demand more rigor from the machine. As long as training data remains unequal, incomplete, or easily manipulable, the problem is not solved by better prompts or larger models. The ultimate responsibility still lies with those who consult, interpret, and decide what to do with the response.
AI can amplify human knowledge, but it can also amplify its defects. And as long as we do not have healthier, more diverse, and well-governed data ecosystems, the only real defense remains the same as always: judgment, contrast, and critical thinking.
Critique, critique, critique
Paraphrasing Julio Anguita with his famous “program, program, program,” what I propose is critical thinking at its highest expression. If we previously had to take the information we received on social media with a grain of salt, it is now much more urgent and necessary.
AI can be a great ally if we use it wisely and cautiously. Dangerous machinery requires appropriate safety measures. AI is not dangerous per se, but it can be if we accept everything it tells us without question. We have the responsibility to harness all the potential it offers without becoming mere passive spectators without judgment.
If you want to remember one phrase, considering that models are our new partners in almost everything we do, I propose the famous line from the song by Presuntos Implicados:
“Distrust your partners.”
1 Before continuing, an important clarification: the examples of biases I propose are not from pure language models, but from image generation. Still, the phenomenon is exactly the same. Whether we talk about text or image, we are dealing with models trained on large volumes of data that reproduce the biases, imbalances, and limitations of what they have seen. The architecture changes; the underlying problem does not.